西风发自凹非寺
量子位公众号 QbitAI
OpenAI 的秘密武器、ChatGPT 背后功臣 RLHF,被开源了。
来自 Hugging Face、加拿大蒙特利尔 Mila 研究所、网易伏羲 AI Lab 的研究人员从零开始复现了 OpenAI 的 RLHF pipeline,罗列了 25 个关键实施细节。
最终成功展示了随着模型大小的增加,响应质量显著提升的 scaling 行为,其中 2.8B、6.9B 的 Pythia 模型在性能上超过了 OpenAI 发布的 1.3B checkpoint。
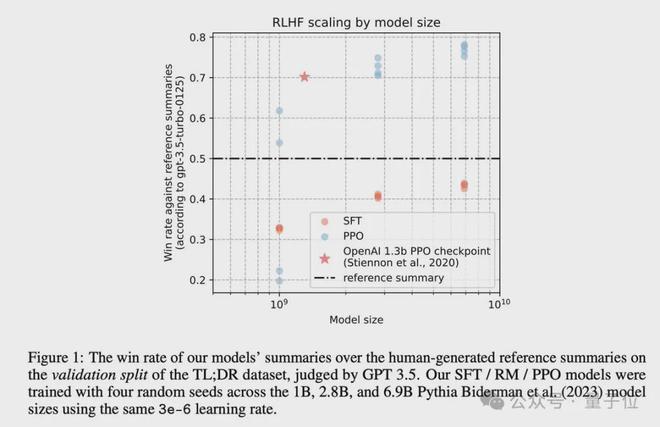
没有写在论文中,但被作者在推文中 po 出来的,还有一个初步的 Pythia 1.4B 实验,根据 GPT-4 的数据显示,这个 1.4B 模型非常接近 OpenAI 的 1.3B 性能(由于 GPT4 成本过高,只进行了一次评估)。
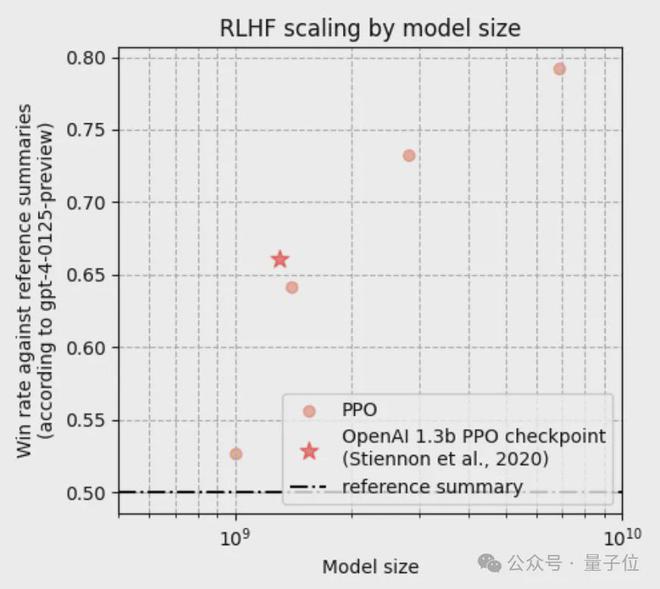
研究人员表示,他们的这一“配方”的独特之处在于对 SFT、RM 和 PPO 使用了单一的学习率,所以再重现他们的工作会变得更加简单。
作者已公开发布了训练好的模型 checkpoint 和代码。

顺便一提,Huggingface 最近上了一把新闻,抱抱脸现在是正式译名了
写在前头
大语言模型的功能实质上就是在玩“词语接龙”——以给定的前面的 token,预测下一个 token。
为了让输出的下一个 token 符合人类意愿,人类反馈强化学习(RLHF)这一方法理念逐渐被引入 pipeline,用于收集成对的人类偏好,训练奖励模型(RM)来对这些偏好进行建模,并使用强化学习(RL)创建一个模型来输出人类喜欢的内容。
OpenAI 对 RLHF 的探索一直走在前头。
在 2020 年“Learning to summarize from human feedback”这项工作中,OpenAI 研究员将 RLHF 应用到了捕捉原始文本主要信息和意图的摘要任务中。
这种人类反馈训练的模型在英文摘要任务上显著优于人类参考摘要和仅使用监督学习的更大模型。且具有较强的泛化能力,在没有特定领域微调的情况下,也能生成高质量的文章摘要,接近人类参考摘要的质量。

在 2022 年“Training language models to follow instructions with human feedback”这项工作中,RLHF 再次被使用,为指令遵循任务而专门设计的InstructGPT诞生。
这也是 GPT-3 到 ChatGPT 的过渡论文。

InstructGPT 的结构和训练技术与 ChatGPT 大差不差,所以也被称为是 ChatGPT 的兄弟模型。而此后 OpenAI 并未放出 ChatGPT 论文,所以有不少学者从 InstructGPT 出发探索 ChatGPT 的内核。
其中秘密武器 RLHF,开源界围绕着它做了不少工作,不过想要重现 OpenAI 的 RLHF pipeline 很是困难。
主要有这么几个原因:
RL 和 RLHF 有许多微妙的实现细节,这些细节对训练稳定性有很大影响; 对于指令遵循任务,如评估一个编码任务中生成的 800 行代码片段的质量,评估模型的表现不太行; 模型需要长时间的训练和迭代。考虑到以上原因,加之总结任务比一般的指令任务更容易评估,所以 Hugging Face 最新的这项工作选择退后一步,从 OpenAI 早期的 RLHF 工作(也就是上面第一篇论文的摘要任务)中,探寻 OpenAI 的 RLHF 的真面目。
25 个细节深度复现
RLHF 通常包括以下三个步骤。
步骤1:训练 SFT(监督微调)策略
使用下一个词预测损失对预训练的 LLM 进行微调,这些微调数据基于人类示范。
在这项复现工作中,人类示范数据与 OpenAI 的工作保持一致,选自过滤后的 Reddit TL;DR(Too Long; Didn’t Read)数据集(当时 OpenAI 还 Open 了他们的人类反馈数据集)。
步骤2:收集偏好对并训练 RM(奖励模型)
使用 SFT 策略等采样不同完成序列,让人类标注员指出他们较偏好的序列。
基于这些偏好数据,通过在 SFT 策略上添加一个随机初始化的线性头来初始化 RM,并优化交叉熵损失函数进行训练,目标是预测人类标注员更倾向于接受哪种完成序列。
步骤3:针对 RM 训练 RL(强化学习)策略
从 SFT 策略初始化,RL 策略根据 RM 对采样的完成序列给出奖励分数,同时加上一个 KL 惩罚项以防止过度偏离 SFT 策略。然后使用 PPO 算法最大化这个 RLHF 目标函数。
研究人员针从数据集到 SFT、RM、OPP,共介绍了 25 个复现细节,深入分析了 TL;DR 数据集的规格、分词过程和分词长度分布。同时,详细描述了 SFT 和 RM 组件的训练设置、实施细节和结果。
感兴趣的家人们可以划到最后查看论文,这里罗列了作者认为有趣的细节。
数据预处理阶段:
对于 RLHF 的提示查询,OpenAI 在最后一段进行截断,而不是使用硬性的截断限制;同时确保“TL;DR:”之后没有多余的空格。

始终在 reference completions 前加上前导空格,在 reference completions 后添加`<endoftext>`,并使用单独的[PAD] token 填充。

SFT 和偏好数据集的 tokenization length 不同,因此在 SFT 和 RM 训练期间分别设置最大 token 长度时需要注意。

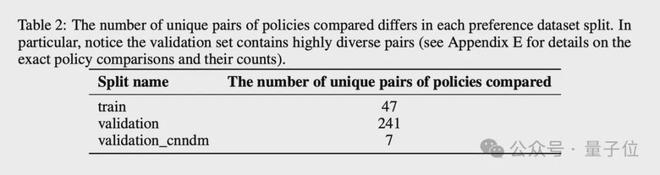
RM 的验证集非常有趣,因为它包含更多独特的策略对进行比较,所以它有很多超出分布的数据。
SFT 阶段:
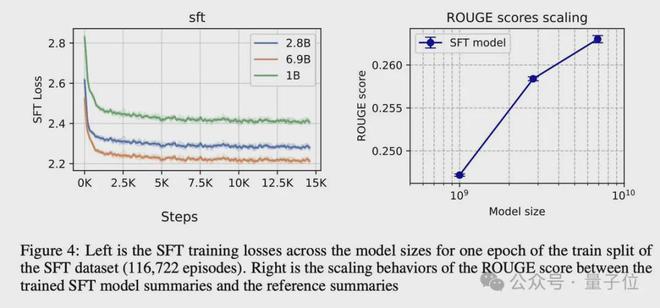
SFT 阶段没有太多的实现细节,只需要标准的下一个 token 预测损失就可以了。除了使用了不同的学习率之外,研究人员的设置几乎与原始设置相同。
损失下降,ROUGE 分数在 4 个随机种子和 3 个模型 checkpoint 大小上都有所提高。
RM 训练:
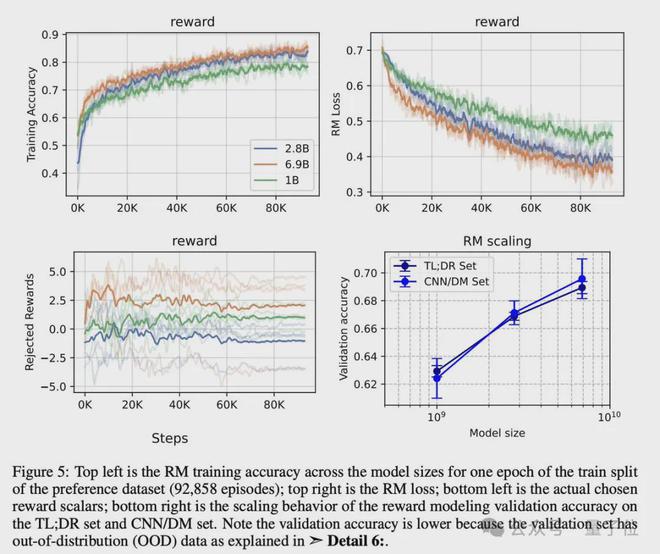
RM 训练更有趣。例如,研究人员发现 RM 只在 EOS token 处提取奖励。此外,在检查奖励的 logits 时,除了 EOS token 外,几乎所有的 logits 都是负数。

结果非常不错,验证准确率提高了,RM 几乎完美地转移到了偏好数据集验证集中的 CNN/DM 子集上。
他们计算了 SFT demonstration 的平均奖励——标量值看起来有些随意;还计算了 OpenAI 偏好数据集中每个批号和置信度的验证准确率。
值得注意的是,不同的批次/置信度可能会有截然不同的准确率。
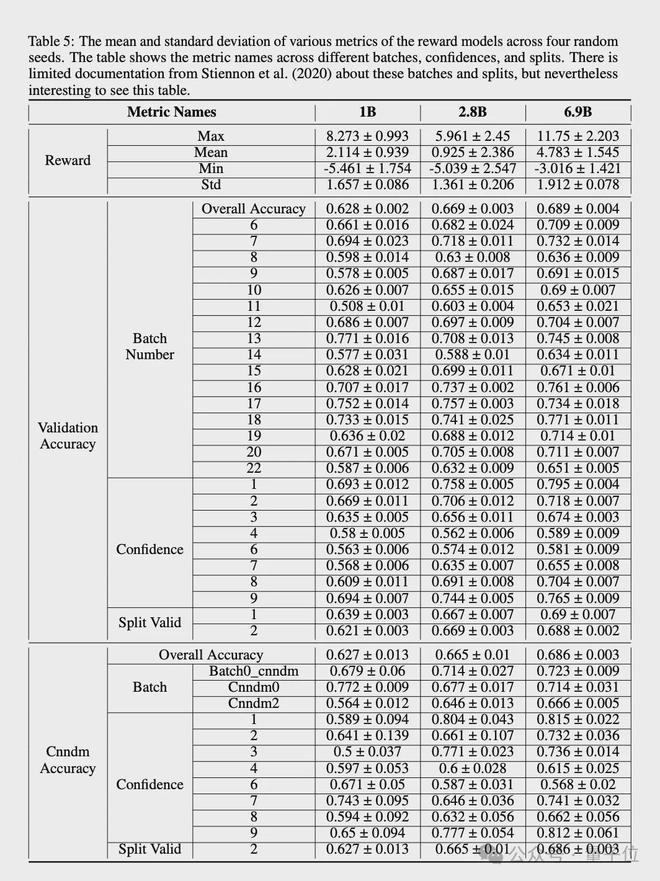
研究人员也测量了 RM 与 GPT3.5 和 RM 的一致性率(agreement rate),并发现一致性率有所提高,但在 6.9B 级别时有所减弱。
并绘制了 AnthropicAI 所做的 RM 校准,发现 RM 通常校准不足。
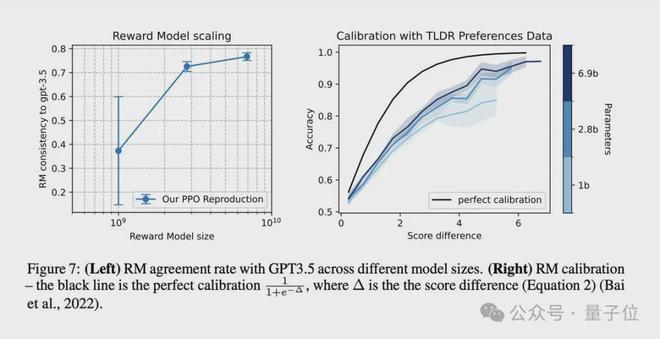
研究人员将验证准确率与 DPO 的隐式 RM 进行了比较,发现出于某种原因 DPO 的验证准确率较低。
几个不同点:
RM 训练只在 EOS token 处应用损失,而 DPO 在每个完成 token 处应用损失。 DPO 还有一个可能影响训练的$beta 参数,RM 则没有。 研究员 Michael Noukhovitch 提出了个有说服力的观点:DPO 的目标可能更难优化,因为你需要使你的 logprobs 与基本模型有足够大的不同才能更改奖励,而 RM 可以学习一个线性头,可以更容易/更快地改变奖励的值。
PPO 训练:
有趣的是,学习值函数的行为与 RM 截然不同。例如,值函数 logits 通常更为正,因为在每个时间步长,它都试图对最终分数进行建模。

PPO 也使用了 EOS 技巧。在 PPO 训练中,研究人员通常采样固定数量的 token,比如 48 个。如果完成不以 EOS token 结束怎么办?前面已经提到了,非 EOS token 的 logits 几乎总是负的(并且可能无效)。
EOS 技巧基本上用恒定的-1 奖励取代了不以 EOS token 结尾的完成的奖励。有几个目的:

研究人员还尝试了 PPO 的奖励白化处理,并发现这样使得与参考摘要的胜率略有降低,以及完成 token 的长度略微缩短。
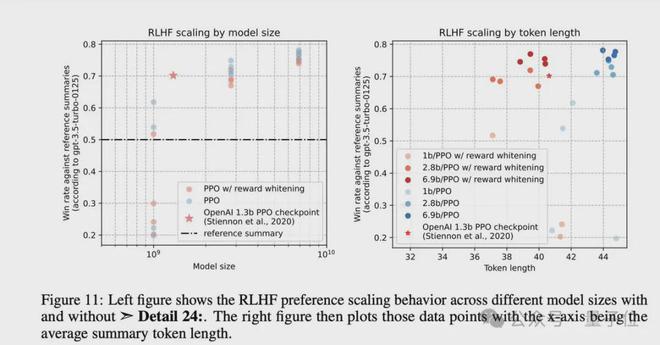
长度在这里是一个混杂因素,所以研究人员引导了 OpenAI 进行的长度控制分析,通过将x轴设置为模型摘要长度与参考摘要长度之比的对数来执行。
当长度得到控制时,研究人员发现比较奖励白化的结果更具挑战性,但尽管如此,在每个摘要长度上,PPO 模型几乎总是优于 SFT 模型。

PPO 的训练曲线如下所示。值得注意的是,几个 1B 型号的 KL 值爆炸了。从优化的角度来看,这并没有什么问题,因为 RLHF 奖励一直在上升,这些 1B 模型对应于“奖励黑客”/过度优化的模型。
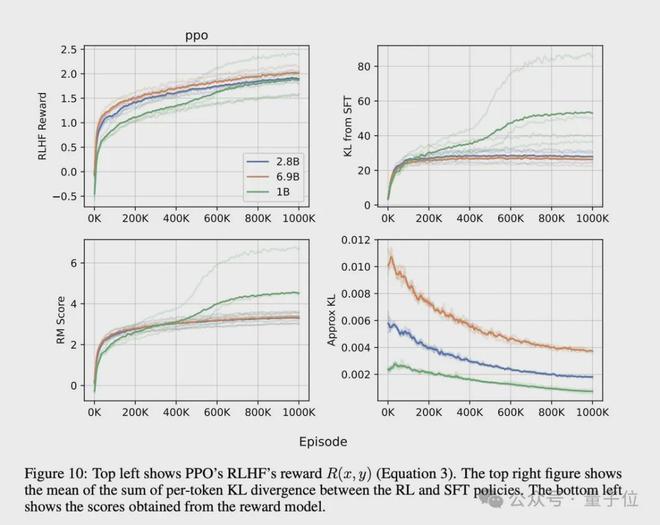
为了更好地理解模型的行为,研究人员还可视化突出显示了经过微调的模型在生成文本时总会以一个 EOS token 结束。为了进一步探索这一点,原论文附录部分提供了更多类似的可视化效果。

论文链接:https://arxiv.org/abs/2403.17031
GitHub 链接:
https://github.com/vwxyzjn/summarize_from_feedback_details https://github.com/vwxyzjn/summarize_from_feedback_details/blob/main/visualize_tokens.py