新智元报道
编辑:alan
在英伟达统治 AI 时代硬件的当下,谷歌的 TPU 却开辟了另一条道路。今天,小编带你了解第一块 TPU 的前世今生,同时揭开 TPU 架构的神秘面纱。
在计算的历史上,曾被丢弃或过时的想法仍然很有趣,有时甚至非常有用。
在这方面,我们这辈子能经历的最重要的例子莫过于神经网络了。
多数人可能都了解,在神经网络近 70 年的历史中,寒冬和泡沫交替出现,——事实上,藏在神经网络背后的专用硬件加速器(ASIC)也是如此。

神经网络和 ASIC 属于是「先有鸡还是先有蛋」的关系,大家都知道神经网络在 CPU 上效率不高,但是,如果没有证据证明神经网络是有用的,公司凭什么要为神经网络投资开发专门的硬件?
然而,正因为没有合适的硬件,神经网络也 work 不起来......
在历史的周期演进中,构建专用硬件的项目一次又一次地被放弃,最终,作为外来者的 GPU 打破了僵局。

毫无疑问,我们现在正处于泡沫周期,在大模型的激励下,从初创公司到超大规模企业,都在构建建立自己的硬件加速器。
他们之中的大多数都可能会失败,但也肯定会有成功的设计成为未来计算领域的重要组成部分。
——而谷歌的张量处理单元(TPU)作为第一批大规模部署的加速器,肯定会成为幸存者之一。
当我们在谈论 TPU 时,我们在谈论什么
为什么谷歌的 TPU 既有趣又重要?因为这是谷歌,TPU 被切实应用于谷歌庞大的服务(搜索、Android、Chrome、Gmail、地图、Play 商店、YouTube、照片),用户超过 10 亿。此外,谷歌还拥有第三大公共云。
在英伟达的 GPU 主导了这个 AI 时代硬件供应的当下,谷歌的 TPU 是一个真正经历了时间和规模考验的竞品。

以下的内容,小编分成两部分:第一部分讲故事,关于第一个谷歌 TPU 的前世今生;第二部分讲技术,揭秘 TPU 的架构细节和性能。
起源
机器学习对谷歌来说是一件大事。毕竟谷歌的既定使命是「组织世界信息,使其普遍可用和有用(to organize the worlds information and make it universally accessible and useful)」。
机器学习帮助谷歌发掘信息的价值,从图像和语音识别到语言翻译,再到大型语言模型,当然也少不了谷歌的「摇钱树」——年入数十亿美元的广告业务。
2010 年代初,谷歌的注意力开始转向深度学习:
2011 年:Jeff Dean、Greg Corrado 和 Andrew Ng 发起了关于深度学习的研究项目——Google Brain。 2013 年:继 AlexNet 图像识别项目取得成功后,谷歌以 4400 万美元的价格收购了由 Geoffrey Hinton、Alex Krizhevsky 和 Ilya Sutskever 组成的初创公司。 2014 年:谷歌收购了由 Demis Hassabis、Shane Legg 和 Mustafa Suleyman 创立的 DeepMind,价格高达 65000 万美元2013 年,当 AlexNet 的开发者 Alex Krizhevsky 来到谷歌时,他发现谷歌现有的模型都在 CPU 上运行。
于是,在公司工作的第一天,他出去从当地的一家电子商店买了一台 GPU 机器,把它插入网络,然后开始在 GPU 上训练神经网络。
最终,大家意识到需要自己需要更多的 GPU,2014 年,谷歌决定以约 13000 万美元的价格购买 40,000 个英伟达 GPU。
深度学习所提供的能力可以大规模应用于谷歌的各种业务,然而,无论是在技术上还是在战略上,依赖英伟达 GPU 都不一定是最佳解决方案。
GPU 不是 ASIC,它不是为神经网络量身打造的,对于需要大规模应用的谷歌来说,相当于要付出很大的额外代价;同时,依赖单一供应商显然也是战略上的重大风险。
谷歌当时有两种选择:现场可编程门阵列(FPGA)和专用集成电路(ASIC)。
当时的实验证明,FPGA 的性能打不过 GPU,而定制 ASIC 可能在推理方面产生 10 倍的性价比优势。
快速交付
开发 ASIC 的时间成本是一个重要的考量,如果落地周期太长,那么硬件本身也就失去了意义。为此谷歌动用了一切可以快速访问的资源和现有知识。
谷歌迅速招募了一支才华横溢、经验丰富的团队,其中包括 David Patterson,——伯克利 RISC 原始设计的开发者,也是 RISC-V 指令集架构开发的关键人物。
为了赶时间,谷歌没有去从头开发新的架构。幸运的是,在 35 年前,就有人为他们准备好了合适的架构。
1978 年,卡内基梅隆大学的H.T.Kung 和 Charles E. Leiserson 发表了《Systolic Arrays (for VLSI)》,提出了「systolic system」。

论文地址:https://www.eecs.harvard.edu/htk/static/files/1978-cmu-cs-report-kung-leiserson.pdf
A systolic system is a network of processors which rhythmically compute and pass data through the system….In a systolic computer system, the function of a processor is analogous to that of the heart. Every processor regularly pumps data in and out, each time performing some short computation so that a regular flow of data is kept up in the network. systolic system 是一个处理器网络,它有节奏地计算并通过系统传递数据......处理器的功能类似于心脏,每个处理器都会定期将数据泵入和泵出,每次都执行一些简短的计算,以便在网络中保持常规的数据流。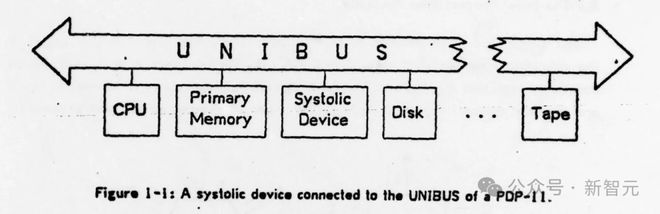
作者同时提出了架构的一种应用:矩阵计算。
Many basic matrix computations can be pipelined elegantly and efficiently on systolic networks having an array structure. As an example, hexagonally connected processors can optimally perform matrix computation......These systolic arrays enjoy simple and regular communication paths, and almost all processors used in the network are identical. As a result, special purpose hardware devices based on systolic arrays can be built inexpensively using the VLSI technology. 许多基本的矩阵计算可以在具有数组结构的脉动网络上优雅而有效地执行流水线。例如,六边形连接的处理器可以最佳地执行矩阵计算......这些脉动阵列享有简单而规则的通信路径,并且网络中使用的几乎所有处理器都是相同的。因此,使用 VLSI 技术可以廉价地构建基于脉动阵列的专用硬件设备。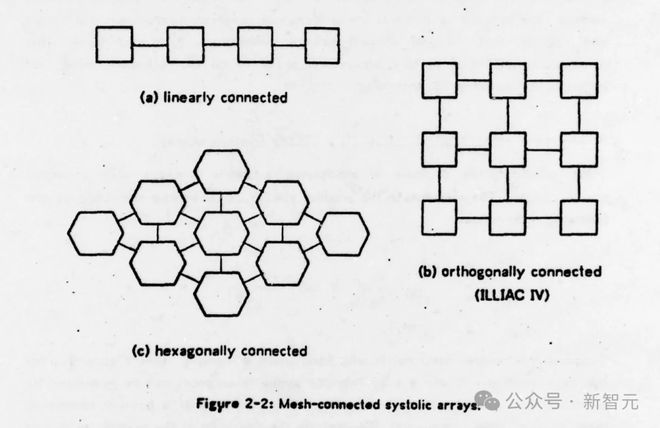
——这不就来了吗!简单、便宜、还适合算矩阵!真是老天爷喂饭吃。
有了工程师和架构之后,谷歌还与当时的 LSI 公司(现在是 Broadcom 的一部分)合作,帮助芯片落地。
另外,全新的芯片意味着需要全新的指令集架构、全新的编译器以及上层软件,这是一个庞大的工程。
2015 年初,第一批 TPU 正式部署在谷歌的数据中心,此时,距离项目启动仅仅过去了 15 个月,看一下这个庞大的研发团队:

论文地址:https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
为了这个进度,谷歌也不得不做了很多取舍,包括使用较老的工艺(28nm),以及较低的时钟频率(700MHz).
2016 年 3 月,使用了 TPU 的 AlphaGo Zero 击败了当时的世界围棋冠军李世石,举世震惊。
TPU 架构
在神经网络的运算中,矩阵乘法是关键,下面是一个简单的例子:

那么,TPU 是如何计算矩阵乘法的呢?
在上面的故事中,我们提到了 TPU 的原理:systolic arrays(脉动阵列),假设有如下的2*2 矩阵乘法:
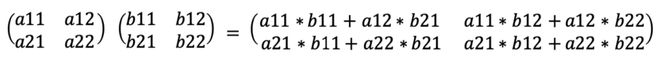
计算结果如下图所示。每个角上的方块代表一个乘法/累加单位 (MAC),可以执行乘法和加法运算。

在此图中,黄色值是从顶部和左侧输入矩阵的输入。浅蓝色值是存储的部分总和。深蓝色值是最终结果。
第一步,a11 和 b11 加载到左上角的 MAC 中,相乘并存储结果。 第二步,a12 和 b21 加载到左上角的 MAC 中,相乘并添加到先前计算的结果中。这一步得到了结果矩阵的左上角值。同时,b11 被传输到右上角的 MAC,乘以新加载的 a21,并存储结果;a11 被传输到左下角的 MAC,乘以新加载的 b12,并存储结果; 第三步,b21 被传输到右上角的 MAC,乘以新加载的值 a22,结果被添加到以前存储的结果中;a12 被传输到左下角的 MAC,乘以新加载的 b22,并将结果添加到先前存储的结果中。此时得到了结果矩阵的右上角和左下角值。同时,a12 和 b21 被传输到右下角的 MAC,相乘并存储结果。 第四步,将 a22 和 b22 传输到右下角的 MAC,相乘并将结果添加到先前存储的值中,从而得到结果矩阵的右下角值。至此,2*2 矩阵乘法完成。
完整计算系统的最简单表示如下:
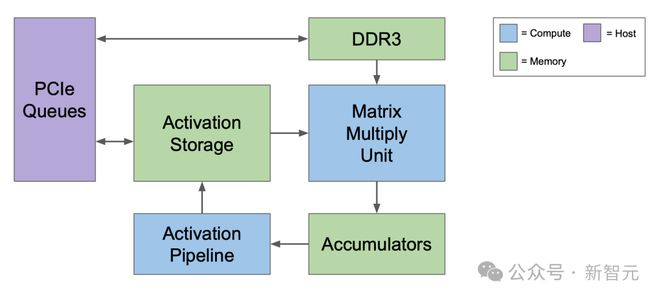
首先要注意的是,TPUv1 依赖于通过 PCIe(高速串行总线)接口与主机进行通信。它还可以直接访问自己的 DDR3 存储,
更详细的设计可以扩展成下图这样子:
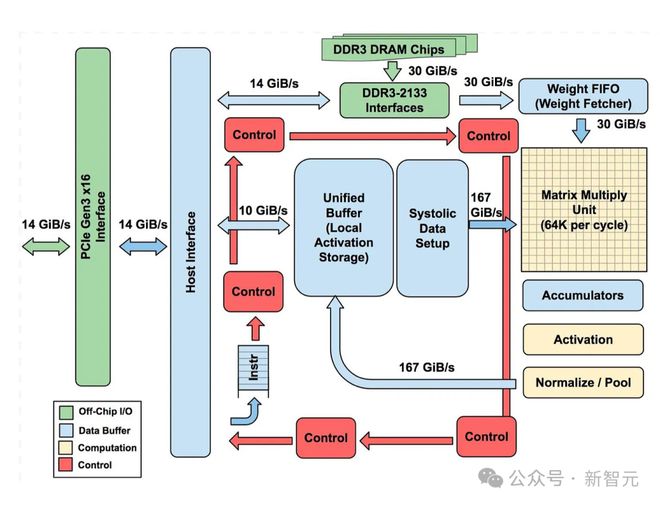
TPU v1 执行 8 位整数乘法,利用量化来避免消耗更大的浮点计算。
TPU v1 使用 CISC(复杂指令集)设计,只有大约 20 条指令。这些指令是由主机通过 PCIe 接口发送给 TPU 的,而不是从内存中获取的。
矩阵运算采用可变大小的B*256 输入,将其乘以 256x256 恒定权重输入,生成B*256 输出,所以需要B次流水线循环才能完成。
TPU 的整个执行过程大概像这样子:
Read_Host_Memory Read_Weights Loop_Start Matrix_Multiply Activate Loop_End Write_Host_Memory由于 TPU v1 的指令集非常简单,可以保证芯片用于解码和相关活动的开销非常低,只有2% 的芯片区域专门用于控制。
而 24% 的芯片面积专用于矩阵乘法单元,29% 用于存储输入和中间结果的统一缓冲区存储器。

2013 年,TPU v1 与英特尔的 Haswell CPU 和英伟达的 K80 GPU 进行了比较:
TPU v1 的 MAC 数量是 K80 GPU 的 25 倍,片上内存是 K80 GPU 的 3.5 倍。 TPU v1 的推理速度比 K80 GPU 和 Haswell CPU 快 15 到 30 倍。 TPU v1 的相对计算效率是 GPU 的 25 到 29 倍。时至今日,这个「临时赶工」的 ASIC,已经不断完善和壮大,在英伟达的统治之下,开辟了另一条道路。

参考资料:
https://thechipletter.substack.com/p/googles-first-tpu-architecture